类命名
- 动词过去式+名词
- contextRefreshedEvent
- 动词ing+名词
- InitialzingBean
- 形容词+名称
- ConfigurableApplicationContext
方法命名
- 方法表示执行动作,通常是动词
- Runnable#run()
- Action#execute()
- Callable#call()
- render()
- 动词+形容词
- Stream.of(1, 2, 3).forEachOrdered(System.out::println)
- 副词形容动词或形容词
- 动词+名词
- getValues()
- 动词+名词+副词
- getValuesSynchronously()
- 动词+副词
- renderSynchronously()
- renderConcurrently()
执行某个方法
- 方法命名:动词
- execute
- callback
- run
- 方法参数:名称
- 异常:
- 根(顶层)异常
- throwable
- checked类型:exception
- unchecked类型:runtimeExcetion
- 不常见:error
- throwable
- 根(顶层)异常
泛型
List<Integer> src = new ArrayList<>();
src.add(1);
src.add(2);
src.add(3);
List<Integer> dest = new ArrayList<>(src.size());
//泛型src为生产者所以用<?extends T> dest为消费者所以用<? surper T>
Collections.copy(dest,src);
System.out.println(dest.size());
查看端口命令
netstat -anp|grep 8888
git pull 跟远程同步流
git branch --set-upstream-to=origin/dev
git reset 回退
git log
git reset --hard HEAD^ 回退到上一个版本
git reset --hard commitID号 //本地端回滚到指定的版本
git checkout -- file 撤销修改的文件(如果文件加入到了暂存区,则回退到暂存区的,如果文件加入到了版本库,则还原至加入版本库之后的状态)
git reset HEAD file 撤回暂存区的文件修改到工作区
git stash 暂存
git stash 暂存当前修改
git stash apply 恢复最近的一次暂存
git stash pop 恢复暂存并删除暂存记录
git stash list 查看暂存列表
git stash drop 暂存名(例:stash@{0}) 移除某次暂存
git stash clear 清除暂存
git add 添加文件
//添加当前下的所有文件
git add .
//添加多个文件,文件之间以空格隔开
git add file1 file2 file3
//多次git add
git add file1
git add file2
git add file2
//强制将文件提交
git add -f 文件名
git merge
//将div合并到当前分支
git merge dev
//不使用Fast forward方式合并,采用这种方式合并可以看到合并记录
git merge --no-ff -m '合并描述' dev
##git commit 提交
git commit --amend //修改最后一次注释
git branch
git branch 创建分支
git branch -b 创建并切换到新建的分支上
git checkout 切换分支
git branch 查看分支列表
git branch -v 查看所有分支的最后一次操作
git branch -vv 查看当前分支
git brabch -b 分支名 origin/分支名 创建远程分支到本地
git branch --merged 查看别的分支和当前分支合并过的分支
git branch --no-merged 查看未与当前分支合并的分支
git branch -d 分支名 删除本地分支
git branch -D 分支名 强行删除分支
git branch origin :分支名 删除远处仓库分支
git merge 分支名 合并分支到当前分支上
git tag
git tag 标签名 //添加标签(默认对当前版本)
git tag 标签名 commit_id //对某一提交记录打标签
git tag -a 标签名 -m '描述' //创建新标签并增加备注
git tag 列出所有标签列表
git show 标签名 //查看标签信息
git tag -d 标签名 //删除本地标签
git push origin 标签名 //推送标签到远程仓库
git push origin --tags //推送所有标签到远程仓库
git push origin :refs/tags/标签名 //从远程仓库中删除标签
git 常规操作
//忽略单个文件
git update-index --assume-unchanged file
//取消忽略文件
git update-index --no-assume-unchanged file
//取消文件被版本控制
git rm -r --cached 文件/文件夹名字(. 忽略全部文件)
git init //初始化
git remote add origin url //关联远程仓库
git pull //拉取
git fetch //获取远程仓库中所有的分支到本地
//拉取、上传免密码
git config --global credential.helper store
Sql复杂语句
###模糊查询
SELECT * FROM st_cards_comment c where c.content LIKE CONCAT('%','靠谱','%');
###逗号分割查询
SELECT GROUP_CONCAT(tag_name) FROM st_cards_custom_tag WHERE FIND_IN_SET(id,'1,2,3');
###根据逗号分隔取多少个
SELECT SUBSTRING_INDEX('3,8,9',',',2);
###排名
SELECT
...
t.rownum
FROM
(
SELECT
...
CASE
WHEN @rowtotal = obj.integral THEN
@rownum
WHEN @rowtotal := obj.integral THEN
@rownum :=@rownum + 1
WHEN @rowtotal = 0 THEN
@rownum :=@rownum + 1
END AS rownum
FROM
(
SELECT
...
(
SELECT
sum(IFNULL(ci.integral, 0)) + IFNULL(i.integral, 0)
FROM
st_flag_company c,
st_company_integral ci
WHERE
c.company_id = ci.company_id
AND c.`enable` = 'Y'
AND c.business_flag_id = f.id
) AS integral
FROM
st_business_flag f
LEFT JOIN st_business_flag_integral i ON i.business_flag_id = f.id
AND i.`enable` = 'Y'
WHERE
f.`enable` = 'Y'
) AS obj,
(
SELECT
@rownum := 0 ,@rowtotal := NULL
) r
ORDER BY
obj.integral DESC,
obj.id ASC
) t
MyBatis
<!-- 循环 -->
...
<if test="cm.userOperationIdList != null and cm.userOperationIdList.size > 0">
and scu.user_id in
<foreach collection="cm.userOperationIdList" item="operationId" open="(" close=")" separator=",">
#{operationId}
</foreach>
</if>
...
<!-- 日期 -->
...
<if test="cm.startTime != null and cm.startTime != ''">
AND DATE_FORMAT(skl.create_time,'%Y-%m-%d %H:%i:%S') <![CDATA[ >= ]]> DATE_FORMAT(#{cm.startTime},'%Y-%m-%d %H:%i:%S')
</if>
<if test="cm.endTime != null and cm.endTime != ''">
AND DATE_FORMAT(skl.create_time,'%Y-%m-%d %H:%i:%S') <![CDATA[ <= ]]> DATE_FORMAT(#{cm.endTime},'%Y-%m-%d %H:%i:%S')
</if>
...
<if test="cm.startTime != null and cm.startTime != ''">
AND DATE_FORMAT(o.contract_begin_time,'%Y-%m-%d') <![CDATA[ >= ]]> DATE_FORMAT(#{cm.startTime},'%Y-%m-%d')
</if>
<if test="cm.endTime != null and cm.endTime != ''">
AND DATE_FORMAT(o.contract_end_time,'%Y-%m-%d') <![CDATA[ <= ]]> DATE_FORMAT(#{cm.endTime},'%Y-%m-%d')
</if>
...
<!-- SQL代码引入 -->
<sql id="base_column">
...
o.id AS id,
o.business_id AS businessId,
o.super_business_id AS superBusinessId,
...
</sql>
...
SELECT
<include refid="base_column"/>
FROM st_company c
...
数据库
- 原子性(Atomicity): 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
- 一致性(Consistency): 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
- 隔离性(Isolation): 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
- 持久性(Durability): 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
| 隔离级别 | 脏读 | 不可重复读 | 幻影读 |
|---|---|---|---|
| READ-UNCOMMITTED(读取未提交) | √ | √ | √ |
| READ-COMMITTED(读取已提交) | × | √ | √ |
| REPEATABLE-READ(可重复读) | × | × | √ |
| SERIALIZABLE(可串行化) | × | × | × |
JAVA命令
#运行jar包命令
java -jar
-XX:MetaspaceSize=128m (元空间默认大小)
-XX:MaxMetaspaceSize=128m (元空间最大大小)
-Xms1024m (堆最大大小)
-Xmx1024m (堆默认大小)
-Xmn256m (新生代大小)
-Xss256k (棧最大深度大小)
-XX:SurvivorRatio=8 (新生代分区比例 8:2)
-XX:+UseConcMarkSweepGC (指定使用的垃圾收集器,这里使用CMS收集器)
-XX:+PrintGCDetails (打印详细的GC日志)
newframe-1.0.0.jar
CURL 命令
curl http://napp1.cn:6060/zy-split-bill-precious-wmg/splitBill/requirement/detail -H 'Content-Type:application/json' -H 'Authorization:Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyX3R5cGUiOiJzdG9yZUZyb250IiwidXNlcl9pZCI6IlNUMzg2Mjc0MWFjZDU1MTFlODlmZjU2YzkyYmY0NzEzMDIiLCJ1c2VyX25hbWUiOiIxODMyMTE4NzcxOSIsInNjb3BlIjpbImFwcCJdLCJleHAiOjI1NDM0NzgyMDcsImF1dGhvcml0aWVzIjpbIlJPTEVfQU5PTlkiXSwianRpIjoiNWEwNTZkODctMmQxNy00YjczLWFjMDQtMTE2MWZkN2JlNWFiIiwiY2xpZW50X2lkIjoic3lzdGVtIn0.v1K9wB14BwQ_s5C7ihaDYbSkxLrBGfjJbqlEm80CXpY' -X POST -d '{"requirementId":104,"source":3}'
类型描述符
- 内部名只能用于类或接口类型。所有其他 Java 类型,比如字段类型,在已编译类中都是用类型。
| Java 类型 | 类型 |
|---|---|
| boolean | Z |
| char | C |
| byte | B |
| short | S |
| int | I |
| float | F |
| long | J |
| double | D |
| Object | Ljava/lang/Object; |
| int[] | [I |
| Object[][] | [[Ljava/lang/Object; |
- 基元类型的单个字符:Z 表示 boolean,C 表示 char,B 表示 byte,S 表示 short,I 表示 int,F 表示 float,J 表示 long,D 表示 double。一个类类型的内部名,前面加上字符 L ,后面跟有一个分号。例如, String 的类型Ljava/lang/String;。而一个数组类型的᧿述符是一个方括号后面跟有该数组元素类型的描述符。
JMX 打开远程监控
###idea工具
-Dcom.sun.management.jmxremote.port=1111
###开启远程jmx访问
JAVA_OPTS="$JAVA_OPTS -Djava.rmi.server.hostname=192.168.1.244"
JAVA_OPTS="$JAVA_OPTS -Dcom.sun.management.jmxremote"
JAVA_OPTS="$JAVA_OPTS -Dcom.sun.management.jmxremote.port=1119"
JAVA_OPTS="$JAVA_OPTS -Dcom.sun.management.jmxremote.ssl=false"
JAVA_OPTS="$JAVA_OPTS -Dcom.sun.management.jmxremote.authenticate=false"
JVM 查看GC信息
jstat -gc pid [interval]
JVM 查看线程栈信息
jstack pid > jstack.log
JVM 查看堆信息
jmap -dump:live,format=b,file=heap201712.hropf 72947
jmap -dump:format=b,file=heap.log pid
JVM 查看线程占用CPU比较高
top -H -p pid
JVM参数设置
1.verbose:gc 表示,启动jvm的时候,输出jvm里面的gc信息。
2.-XX:+printGC 这个打印的GC信息跟上个一样
3.-XX:+PrintGCDetails 打印GC的详细信息。
4.-XX:+PrintGCTimeStamps 打印GC发生的时间戳。
5.-X:loggc:log/gc.log 这个就表示,指定输出gc.log的文件位置。
6.-XX:+PrintHeapAtGC 表示每次GC后,都打印堆的信息。
7.-XX:+TraceClassLoading 监控类的加载。
8.-XX:+PrintClassHistogram 跟踪参数。
9.-XX:NewRatio 新生代和老年代的比例。比如:1:4
10.-XX:SurvivorRatio 设置两个Survivor区和eden区的比例。比如:2:8
11.-XX:+HeapDumpOnOutMemoryError 发生OOM时,导出堆的信息到文件。
12.-XX:+HeapDumpPath 导出堆信息的文件路径。
13.-XX:OnOutOfMemoryError 当系统产生OOM时,执行一个指定的脚本,这个脚本可以是任意功能的。
14.-Xmx -Xms 这个就表示设置堆内存的最大值和最小值。
15.-Xmn 设置新生代的内存大小。
16.-XX:MaxNewSize=512m 新生代内存的最大可分配大小
17.-Xss 设置栈的大小。栈都是每个线程独有一个,所有一般都是几百k的大小。
18.-XX:PermSize -XX:MaxPermSize 设置永久区的内存大小和最大值。
MVN 运行时指定本地仓库位置
mvn clean install -Dmaven.repo.local=/home/juven/myrepo/
MVN 查找依赖树命令
使用 mvn dependency:tree 即可展示全部的
可以加上Dincludes或者Dexcludes进行筛选格式 groupId:artifactId:version的方式进行过滤
例如: mvn dependency:tree -Dverbose -Dincludes=com.google.guava:guava
MVN 编译命令
mvn -Dmaven.test.skip=true -U clean package
MVN mvn下载源码
mvn dependency:sources
MVN 生命周期
<!-- compile 默认就是compile,compile表示被依赖项目需要参与当前项目的编译,当然后续的测试,运行周期也参与其中,是一个比较强的依赖。打包的时候通常需要包含进去-->
<!-- test 测试代码的编译,执行。比较典型的如junit。 -->
<!-- runtime 无需参与项目的编译,不过后期的测试和运行周期需要其参与-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<!-- provided 打包的时候可以不用包进去-->
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<scope>provided</scope>
</dependency>
<!-- system 从本地文件系统拿,一定需要配合systemPath属性使用-->
<dependency>
<groupId>trz-netwk-api</groupId>
<artifactId>trz-netwk-api</artifactId>
<version>1.7.1.570</version>
<scope>system</scope>
<systemPath>${project.basedir}/lib/trz-netwk-api-1.7.1.570.jar</systemPath>
</dependency>
<!-- optional jar是否传递依赖 true表明不会传递依赖-->
<dependency>
<groupId>com.zy</groupId>
<artifactId>zy-common</artifactId>
<version>1.0.0</version>
<optional>true</optional>
</dependency>
<!-- exclusions 用来排除jar包 -->
<dependency>
<groupId>sample.ProjectA</groupId>
<artifactId>Project-A</artifactId>
<version>1.0</version>
<scope>compile</scope>
<exclusions>
<exclusion>
<groupId>sample.ProjectB</groupId>
<artifactId>Project-B</artifactId>
</exclusion>
</exclusions>
</dependency>
SHELL 查看所有开放的端口
netstat -ntlp
SHELL 模糊匹配文件中的字符串内容
find . | xargs grep -ri 'content'
##SHELL 模糊查询文件名
find ./ -name '*0.0.1*.jar.pid'
SHELL 日志重定向到null
nohup java -jar microboot.jar > /dev/null 2>&1 &
阿里图片域名地址
https://ossstaticimg.dianpiao360.com/dp_prod/
从输入URL到页面加载发生了什么
DNS解析->TCP连接->发送HTTP请求->服务器处理请求并返回HTTP报文->浏览器解析渲染页面->连接结束
索引优缺点
优点:
1.大大加快数据的检索速度;
2.创建唯一性索引,保证数据库表中每一行数据的唯一性;
3.加速表和表之间的连接;
4.在使用分组和排序子句进行数据检索时,可以显著减少查询中分组和排序的时间。
缺点:
1.索引需要占物理空间。
2.当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,降低了数据的维护速度。
GC 垃圾回收
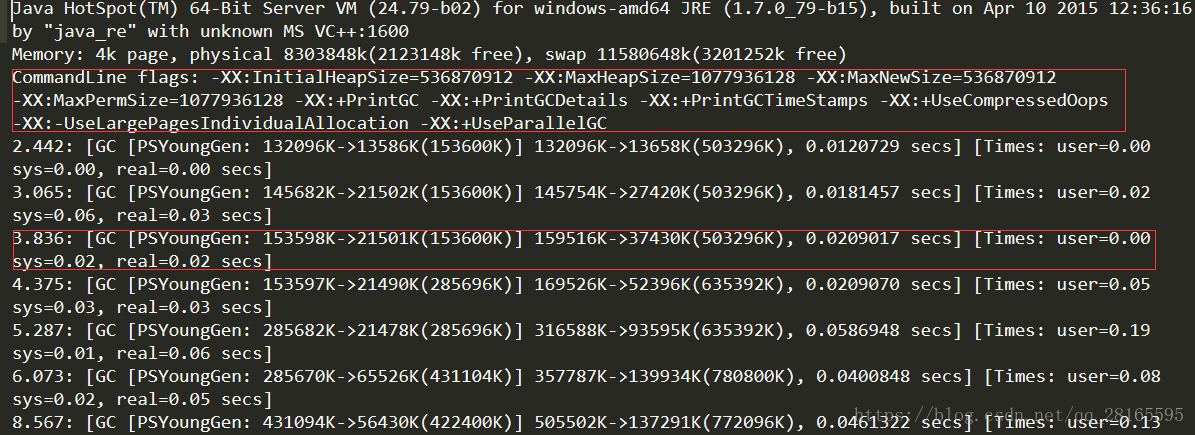
1. 对于3.836 这是具体发生GC的时间点。这是时间戳是从jvm启动开始计算的,我们也可以用PrintGCDateStamps 来打印时间日期格式的时间。
2. PSYoungGen是指GC发生的区域,其实应该还有一个ParOldGen,(因为JVM刚启动没有触发老年代的GC,所以日志上没有展示ParOldGen)分别代表使用Parallel Scavenge垃圾收集器的新生代和使用Parallel old垃圾收集器的老生代。为什么是这两个垃圾收集器组合呢?因为我的jvm开启的模式是Server,而Server模式的默认垃圾收集器组合便是这个,在命令行输入java -version就可以看到自己的jvm默认开启模式。还有一种是client模式,默认组合是Serial收集器和Serial Old收集器组合。
3. 153598K->21501K(153600K),这三个数字分别对应GC之前占用年轻代的大小,GC之后年轻代占用,以及整个年轻代的大小。
4. 159516K->37430K(503296K),这三个数字分别对应GC之前占用堆内存的大小,GC之后堆内存占用,以及整个堆内存的大小。
5. 0.0209017是该时间点GC占用耗费时间。
————————————————
版权声明:本文为CSDN博主「爱琴孩」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_28165595/article/details/82431226
GC (Allocation Failure)-GC类型表示Major GC
Full GC (Ergonomics) -GC类型表示Full GC
[PSYoungGen: 1946K->504K(2560K)]
[新生代:gc回收前该内存区域已使用容量->gc回收后该内存区域使用容量(该内存区域的总容量)]
也就说:新生代 gc回收前:该区域已使用1946k
gc回收后:该区域已使用504k
gc释放了 1946 - 504 = 1442 k的空间
新生代的总大小为:2560k
[ParOldGen: 6344K->1680K(7168K)] ---老年代类比新生代
[Metaspace: 3486K->3486K(1056768K)] ---永久代类别新生代
8090K->6840K(9728K), 0.0019093 secs
gc前Java堆已使用容量->gc后Java堆已使用容量(Java堆的总容量-已分配), PSYoungGen回收gc耗时
也就是说 gc释放了 8090 - 6040 = 2050k的空间
Java堆已分配的大小为 9728k
[Times: user=0.00 sys=0.00, real=0.00 secs]
[Times: 用户消耗的cpu时间 内核态消耗的cpu时间, 操作从开始到结束所经过的墙钟时间即实际消耗的时间]
也就是说 user+sys是cpu时间
cpu时间和墙钟时间的差别是,墙钟时间包括各种非运算的等待耗时,
例如等待磁盘I/O、等待线程阻塞,而cpu时间不包括这些耗时。
Reference
软引用:SoftReference 触发gc原因 其引用的对象在内存不足的时候会被回收。只有软引用指向的对象称为软可达。
弱引用:WeakReference 触发gc原因 当一个对象仅仅被weak reference,而没有任何其他strong reference。
Final引用:FinalReference 由JVM来实例化,VM会对那些实现了Object中finalize()方法的类实例化一个对应的FinalReference。
虚引用:PhantomReference 被回收